Теория баз данных
Использование и разработка баз данных (БД) является одним из основных направлений программирования. Спектр применения БД чрезвычайно широк: практически, каждое предприятие имеет собственные базы данных, в которых, как минимум, производится бухгалтерский и складской учет, а в более крупных компаниях при помощи БД обслуживается весь цикл функционирования бизнеса. Создание БД и приложений для работы с ними - одно из основных предназначений среды Delphi.
Введение в базы данных
Прежде всего, база данных обеспечивает хранение информации и предоставляет средства для доступа к ней. Для создания, ведения и использования БД используют системы управления базами данных - СУБД.
СУБД бывают персональными и многопользовательскими. Наиболее известными локальными СУБД являются Access, FoxPro, Paradox и DBASE, а многопользовательскими - DB/2, Oracle, MS SQL Server и Interbase. Что касается Delphi, то, хотя ее и нельзя назвать СУБД как таковой, однако ее возможности по работе с БД настолько широки, что зачастую она превосходит по ним специализированные СУБД.
При этом базы данных, как и системы, их обслуживающие, подразделяются на 2 категории: локальные и клиент-серверные. Соответственно, и приложения, используемые для работы с теми или иными БД, будут либо локальными, либо клиентсерверными. Основное отличие клиентсерверных приложений состоит в том, что они могут работать с удаленными БД, в то время как локальные - только с теми, что находятся на этом же ПК (максимум - в пределах доступного сетевого диска). При этом локальные приложения так же называются одноуровневыми приложениями, а клиентсерверные бывают двух- или многоуровневыми, при этом, в любом случае, в них различают клиентскую и серверную части.
ПРИМЕЧАНИЕ
На самом деле, для работы клиентсерверного приложения вовсе не обязательно использовать 2 компьютера, один ПК может иметь обе части приложения. Важно лишь, что к серверной части могут подключиться другие ПК.
Фактически, классификация СУБД на персональные и многопользовательские совпадает с разделением БД на локальные и клиент-серверные. Т.е. персональные СУБД, как правило, работают с локальными БД, а многопользовательские - с клиент-серверными. И действительно, например Access является типичной персональной СУБД, работающей с локальной базой. При этом потенциальная возможность обслуживания запросов от нескольких клиентов (для случая размещения БД на файлсервере) не делает подобную СУБД истинно многопользовательской.
Но существует еще одни критерий классификации БД - по организации хранения данных, по которому они подразделяются на 3 принципиально разных типа. Это реляционные БД, иерархические БД и сетевые БД. Практически все современные БД относятся к реляционным, концепция которых была разработана на рубеже 60х-70х годов компанией IBM.
Все уже названные СУБД предназначены для работы именно с реляционными базами данных. Особенности реляционных БД сводятся к следующим ключевым моментам:
- Все данные хранятся в таблицах, состоящих из столбцов и рядов;
- Связи между данными в различных таблицах организованы не явно, а по совпадению каких-либо ключевых значений (или по отношениям - relation);
- Каждый столбец имеет собственное имя и содержит данные только одного, явно заданного типа;
- Порядок столбцов и типы значений определяются в момент создания таблицы. При этом любая таблица должна иметь хотя бы 1 столбец;
- Ряды значений никак не упорядочены, но их можно упорядочить при обработке запроса;
- Запросы к реляционным БД возвращают результат в виде таблицы, которая, в свою очередь, так же может быть использована для запроса.
В целом к достоинствам реляционной модели данных относят простоту и удобство их реализации, а так же гибкость структуры. Из недостатков можно выделить, пожалуй, только возможность потери целостности данных, что вызвано отсутствием жестких связей между данными таблиц. В этой книге мы будем рассматривать только реляционные базы данных.
Таблицы
Таблицы, образующие БД, физически расположены в определенном каталоге на жестком диске. Обычно они хранятся в отдельных файлах, каждый из которых представляет собой отдельную таблицу или файл с дополнительной информацией (с ключами, индексами и т.п.) по таблице. В этом случае имя файла с таблицей, содержащей сами данные, совпадает с именем таблицы, заданным при ее создании. Остальные файлы, имеющие отношение к этой таблице, получают имена автоматически, при этом имя файла у них будет отличаться только расширением. В то же время, в некоторых СУБД принят режим хранения всех данных в одном файле, например, так устроено хранение данных в Access и в Interbase.
Каждая таблица БД представляет собой некоторое подобие электронной таблицы, наподобие тех, что используются в Excel. Но при этом имеется разница, как в реализации, так и в терминологии: В частности, столбцы таблицы БД называются полями, а ряды (строки) - записями. Каждое поле в таблице должно иметь уникальное имя. Так же, как уже отмечалось, в реляционных БД для каждого поля должен быть жестко задан тип данных, например, строковой, целочисленный или вещественный, и записи, хранящиеся в таблице, могут иметь данные только того типа, что предусмотрены полями.
Конкретный перечень поддерживаемых типов данных зависит от применяемой СУБД, хотя все они поддерживают, как минимум, все простые типы данных, принятых в Delphi, а именно: строки, целые числа, вещественные числа, булевы значения, а так же тип даты и времени. Еще одним часто встречающимся в БД типом данных является бинарный объект (Blob, Binary), предназначенный для хранения практически любой информации, будь то форматированный текст, графическое изображение, или вообще данные файла произвольного типа. При этом, как правило, в самом файле табличных данных хранятся лишь ссылки на подобные объекты, которые "упаковываются" в отдельный файл, связанный с данной таблицей.
Для оптимизации размеров БД обычно предусмотрено по нескольку типов целых чисел, как минимум, от 1- до 4-байтовых - Byte, Shortint (Word) и Longint (Double Word). Что касается строк, то их максимальная длина обычно так же лимитируется. Многие современные СУБД так же позволяют работать с полями переменной длины, это относится как к строковым, так и к бинарным типам.
Таким образом, основой каждой таблицы является описание ее полей. А учитывая то, что любая таблица должна иметь хотя бы одно поле, то при создании таблицы, помимо ее имени, указывают и ее структуру, с минимальном случае состоящую из описания единственного поля. В целом же структура таблицы может включать в себя следующие составные части:
- описание полей;
- индексы;
- ключи;
- ограничения на значения;
- пароли и права доступа.
Разумеется, что поддержка той или иной возможности зависит от используемой СУБД, в частности dBase не работает с ключами. Впрочем, ключи и индексы будут подробно рассмотрены чуть позже.
После создания таблицы можно реструктуризировать, меняя количество, имена и типы полей. Однако на изменения полей налагается ряд ограничений, в частности, можно только преобразовывать типы между родственными типами, например, можно изменить тип данных с короткого целого на длинное целое или на вещественное. Однако обратная операция, скорее всего, будет невозможна, равно как и попытка изменения строкового значения на числовое и т.д. Поэтому очень важно изначально разработать как можно более точную и правильную структуру. Для этих целей следует предварительно произвести анализ данных, которые будут храниться как в БД в целом, так и в создаваемой таблице в частности.
Другим изменением, доступным после создания таблицы, является возможность ее переименования. Здесь следует отметить, что если поля в пределах каждой таблицы должны иметь уникальное имя, то в пределах БД каждая таблица так же должна иметь собственное, уникальное название. Важно отметить, что даже если выбранная СУБД хранит все данные в отдельных файлах, переименование таблиц следует делать не путем непосредственного переименования файла с данными (например, в Проводнике Windows), а средствами самой БД, т.к. надлежащим образом должны быть переименованы и все связанные с данной таблицей файлы.
Наконец, таблицу можно просто удалить. Пожалуй, это единственная операция, которую можно сделать, удалив файл непосредственно, воспользовавшись средствами файловой системы, без участия СУБД. Но, разумеется, это возможно лишь в том случае, если используемая СУБД хранит каждую таблицу в отдельном файле. В целом же любые операции лучше производить все-таки средствами самой СУБД, поскольку это послужит некоторой гарантией тому, что операция пройдет без ущерба для остальных данных.
Ключи и индексы
Поскольку реляционные БД не имеют жесткой связи между данными, хранящимися в разных таблицах, данная задача возлагается на разработчика БД. Так же остается открытым вопрос упорядочивания данных. Для данных целей предусмотрены, соответственно, ключи и индексы. При этом ключ, иногда так же называемый первичным индексом, служит для однозначной идентификации каждой отдельной записи в таблице. Ключи бывают простыми, состоящими из одного поля, и составными, объединяющими несколько полей. То поле или поля, по которым построен ключ, называются ключевыми полями таблицы. При этом в каждой таблице может быть определен только один ключ.
Помимо однозначной идентификации записи и установки связей между разными таблицами, ключ так же обеспечивает ускорение обращения к БД, включая такие операции, как поиск и сортировка данных.
Информация о ключе обычно хранится в отдельном файле, причем хранятся они, в отличие от самих записей, в упорядоченном виде. Для каждого значения ключа имеется уникальная ссылка, указывающая на расположение соответствующих этому значению данных в основной таблице. Поэтому при поиске информации по ключу вместо последовательного просмотра данных самой таблицы, СУБД просматривает значения ключей, и сразу переходит в нужное место основной таблицы. Фактически, ключ представляет собой специальную таблицу, служащую для обеспечения быстрого доступа к данным основной таблицы.
Обратной стороной использования ключей является увеличение размеров БД из-за необходимости хранения информации о ключах. При этом размер, занимаемый ключами, зависит не только от количества записей, но и от числа полей, образующих ключ и от их типа данных, поскольку в ключевом файле хранятся не только ссылки, но и сами значения ключевых полей.
Для ключей существуют определенные правила. Прежде всего, ключ должен быть уникальным. При этом уникальность может быть основана как на заведомо неповторяющихся значениях одного поля, так и на заведомо невозможном повторении сразу всех значений, используемых в составном ключе. Скажем, если у нас имеется таблица сотрудников, то в качестве единственного ключевого поля можно использовать ИНН, поскольку он заведомо уникален для каждого человека, за чем зорко следят налоговые органы. Если же такой информации не предусмотрено, то ключ можно установить, скажем, по 2 полям, скажем, по имени и дате рождения, поскольку использование только одного из этих полей мало приемлемо на случай совпадения имен или, тем более, дат рождения. Вероятность же совпадения обоих значений сразу, фактически, нулевая (если только вы не делаете БД для переписи населения).
Другим правилом является принцип разумной достаточности и неизбыточности. В частности, для составного ключа не должны быть использованы поля, удаление или изменение которых может привести к нарушению уникальности ключа. В то же время, для оптимизации размеров и быстродействия БД ключ не должен содержать лишнюю информацию. В частности, для рассмотренного примера с таблицей сотрудников нет необходимости использовать более 1 поля, если ключ построен по ИНН, или задействовать, скажем, еще и поле с информацией о поле сотрудника, когда уже задействовано имя.
Впрочем, в ряде случаев использование каких-либо полей, предусмотренных необходимой структурой БД, в качестве ключевых неоправданно. Допустим, у нас имеется таблица номенклатуры товаров, имеющую поля типа названия товара, его параметров (скажем, цвет, фасон и размер) и цены. Пусть нем будет запись типа "Рубашка х/б, белая, длинный рукав, 46-48, 300р.". В данном случае создание индекса даже по всем полям, в общемто, не гарантирует его уникальности, не говоря уже об его эффективности. В такой ситуации обычно добавляют дополнительное поле, задающее заведомо уникальный идентификатор товара - ID, или артикул, и назначают индексом именно его. В качестве подобных полей часто используют поле специального автоинкрементного типа, предусмотренного в некоторых СУБД, например, в Paradox. В таком случае при создании новой записи значение в это поле заносится автоматически самой СУБД, при этом оно будет на 1 больше предыдущего. Если же автоинкрементного типа не предусмотрено, то используют специальные триггеры и генераторы (в Interbase), или создают код каким-либо иным программным способом.
Помимо рассмотренных ключей - первичных индексов, существуют обычные индексы. В отличие от первичных, они могут содержать повторяющиеся значения. Кроме того, в таблице может быть несколько индексов. Подобно ключам, индексы могут быть построены по одному или по нескольким полям таблицы. Те поля, по которым построен индекс, называются индексными, а сам процесс построения индекса называют индексированием таблицы.
Индексы предназначены для обеспечения ускоренного доступа к данным, включая поиск и сортировку. Так же индексы могут быть использованы для установления связей между таблицами. В последнем случае индекс обычно используется совместно с ключом из другой таблицы.
ПРИМЕЧАНИЕ
Следует учитывать, что сортировка данных в некоторых случаях (например, при использовании объекта Table) возможна только по индексированным полям. Вместе с тем, если даже использовать другие способы для доступа к данным, сортировка по проиндексированным полям происходит быстрее.
Как уже было отмечено, для каждой таблицы можно определить несколько индексов. При этом в один момент времени любой из них можно выбрать в качестве активного, т.е. того, по которому будет производиться выборка и сортировка данных таблицы.
В сумме использование ключей и индексов позволяет эффективно реализовывать следующее:
- добиться однозначной идентификации записей и избегать дублирования ключевых значений;
- устанавливать связи между отдельными таблицами;
- ускорять (а в некоторых случаях - вообще делать возможной) сортировку, а так же поиск в таблицах.
Таким образом, скорость работы БД, равно как и целостность хранимых в ней данных во многом обеспечиваются как раз правильным подбором ключей и индексов в таблицах.
Организация данных и связь между таблицами
При рассмотрении ключей и индексов мы много раз упоминали про организацию связи между различными таблицами в рамках БД. И хотя теоретически БД может состоять из одной единственной таблицы, содержащей лишь имена и даты рождения сотрудников, на практике СУБД для подобных целей не применяются: такую информацию можно хранить в виде электронной таблицы, а то и вообще в обычном текстовом файле. Поэтому рассмотрим более типичную ситуацию, когда БД состоит из нескольких взаимосвязанных таблиц.
Организация отношений между таблицами называется связыванием, или соединением таблиц и является одним из ключевых моментов разработки БД. Связи задаются как при создании таблиц (назначение ключей и индексов), так и в процессе разработки и даже работы приложения, для чего используются различные средства, предоставляемые СУБД.
Для связывания таблиц используют поля, называемые полями связи. Такие поля должны быть индексированными. При связывании таблиц одна из них назначается главной (Master), а другая - подчиненной (Slave, Detail). При этом индекс, отвечающий за соединение в подчиненной таблице, называют внешним ключом. Что касается главной таблицы, то ее поле, участвующее в связывании, должно быть главным индексом (разумеется, если в применяемой СУБД есть такое понятие). Типы полей, участвующих в связывании, должны совпадать, например, оба они должны быть целочисленными.
Допустим, у нас имеется БД, состоящая из 2 таблиц, в одной из которых хранится список клиентов (назовем ее CUSTOMER), а в другой - накладные, выписанные этим клиентам (BILL). В таком случае ключом первой таблицы должен быть идентификатор клиента (скажем, поле автоинкрементного типа CUST_ID), а во второй должно иметься, по возможности, индексированное поле, содержащее информацию о том, какому клиенту выдана данная накладная (поле BILL_CUST). При этом ключевым полем второй таблицы будет номер накладной (поле BILL_ID). В получившейся связи связанными полями будут CUST_ID и BILL_CUST, причем последнее будет являться внешним ключом для таблицы BILL (рис. 17.1).
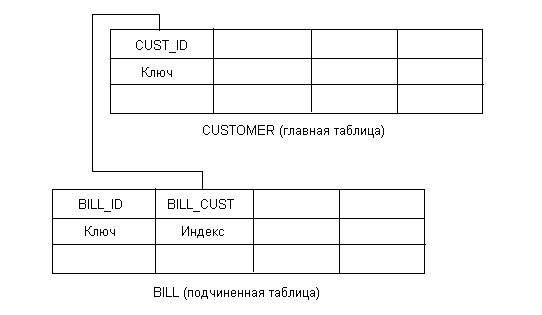
Рис. 17.1. Связи между таблицами
Связать между собой можно 2 таблицы или несколько таблиц сразу. При этом одна из таблиц обычно выступает главной, а другие - подчиненными. Такую связь обычно называют "главный-подчиненный". Вообще же, в зависимости от заданных условий, эта связь может получиться одного из 4 видов:
- "Один к одному", когда каждой записи в главной таблице соответствует 1 запись в подчиненной;
- "Один ко многим", когда каждой записи в главной таблице соответствует 0 или больше записей в подчиненной;
- "Много к одному", когда нескольким записям в главной таблице соответствует 1 в подчиненной;
- "Много ко многим", когда произвольному числу записей в главной таблице соответствует такое же неопределенное число записей в подчиненной.
Чаще всего встречается 2-й вариант, включая рассмотренный пример, где каждой записи о клиенте может соответствовать произвольное число записей в таблице накладных, включая полное их отсутствие, если клиент еще ничего не купил.
После того, как связь между таблицами установлена, выбор определенной записи в главной таблице автоматически приведет к выборке в подчиненной (рис. 17.2).
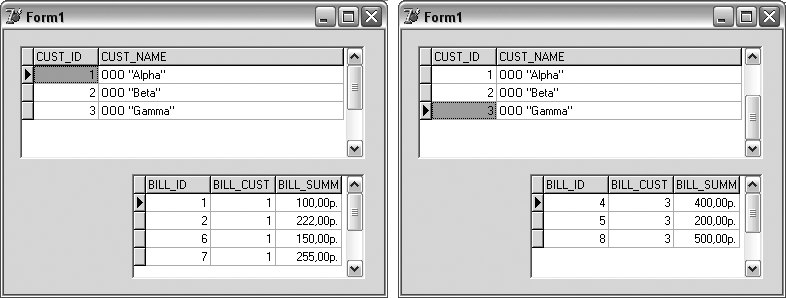
Рис. 17.2. Связь "один ко многим", связанные поля BILL_CUST и CUST_ID
Хотя технология связывания таблиц средствами IDE будет рассматриваться позже, забегая вперед, отметим, что в данном случае для таблицы BILL была выбрана Master-таблица CUSTOMER и была установлена связь через объединение полей типа BILL_CUST ' CUST_ID (подробнее см. в главе 19).
Целостность БД и транзакции
При проектировании приложений БД следует учитывать взаимосвязь между таблицами. Например, для того, чтобы не допустить появления в таблице накладных "потерянных" записей, не относящихся ни к одному из клиентов, при удалении записи в таблице CUSTOMER следует выполнять проверку таблицы BILL на наличие накладных, имеющих отношение к данному клиенту и удалять их. Если же информация о счетах важна, скажем, для ведения статистики продаж, то следует изменять значение в поле BILL_CUST на какого-либо "клиента по умолчанию". В то же время, при добавлении записи в подчиненную таблицу надо заботиться о том, чтобы во внешнем ключе было установлено верное значение, ссылающееся на главную таблицу.
Сами ограничения по установке, изменению и удалению полей в связанных таблицах могут быть наложены при создании таблиц средствами, предоставляемыми СУБД, параллельно описанию полей и индексов. В таком случае данные ограничения будут являться частью структуры таблиц, и за их выполнением будет следить СУБД. В то же время, эти ограничения могут и не являться частью структуры БД, в таком случае за их выполнением должен будет следить разработчик при создании приложения. Например, если производится попытка удалить запись из главной таблицы (скажем, из CUSTOMER), то при этом должны быть произведена проверка подчиненной таблицы (BILL). И, в зависимости от логики программы, должны будут либо удалены все записи, относящиеся к данному клиенту в таблице накладных, либо удаление клиента должны быть запрещено. В любом случае при этом полезно выдавать предупреждающее сообщение оператору, работающему с приложением БД.
Подобное поведение БД, когда действие в одной таблице порождает ряд действий в других (например, то же удаление в подчиненных таблицах), называется каскадированием. Каскадирование, как и иные описанные выше шаги, направлены на обеспечение целостности БД. При каскадировании может быть выбран различный порядок выполнения операций: например, можно сначала удалить запись в главной таблице, после чего удалить записи в подчиненной, а можно наоборот, сначала удалить записи в подчиненной, после чего - удалить в главной. Но в любом случае остается открытым вопрос обеспечения целостности БД на случай непредвиденных сбоев, как-то отключения электропитания, разрыва соединения (при работе с удаленной БД) и иных неприятностей. В таком случае может возникнуть ситуация, когда в одной таблице данные будут удалены, а в другой - нет, в результате чего целостность данных будет нарушена.
На помощь в таких ситуациях приходит использование механизма транзакций. Транзакция представляет собой выполнение последовательности операций как общего целого. При выполнении транзакции возможно 2 варианта:
- все операции успешно выполнены. В таком случае транзакция считается успешной, изменения записываются во все таблицы и БД в результате переходит из одного целостного состояния в другое;
- одна или более операций завершена неудачно. В таком случае транзакция считается неуспешной и результаты всех(!) операций, образующих данную транзакцию, отменяются, и БД остается в целостном состоянии.
Использование транзакций крайне необходимо в таких случаях, когда выполняются сложные каскады операций, а так же при многопользовательском доступе к БД.
Транзакции бывают неявными, когда она стартует и завершается автоматически, за что отвечают механизмы СУБД, а так же явными, когда за их выполнение отвечает программный код создаваемого приложения БД. Например, для переноса данных из одной таблицы в другую, можно начать транзакцию при считывании и удалении данных из одной таблицы и завершить - после внесения записи в другую. В противном случае (без использования механизма транзакций) мы могли бы столкнуться с такой ситуацией, что в данных не окажется ни в одной из таблиц, или, наоборот, часть данных окажется продублированной в обоих.
В дополнение к вопросу целостности и транзакций следует упомянуть про такое понятие, как бизнес-правила. Бизнес-правила предназначены для выполнения целого ряда действий, облегчающих работу с БД, в том числе и поддержание базы в целостном состоянии:
- задание значений по умолчанию для полей таблиц;
- запрет пустого значения;
- требование уникального значения;
- определение допустимого диапазона значений;
- ограничение ссылочной целостности.
Обычно бизнесправила задаются при создании таблиц, хотя ничего не мешает установить их, или дополнить на программном уровне уже в процессе разработки приложения.
Язык SQL
Рассказывая о реляционных базах данных, невозможно не упомянуть о таком инструменте, как SQL - Structured Query Language (язык структурных запросов). Язык SQL предназначен для создания запросов к базам данных и существенно отличается от других языков программирования, в том числе от Delphi.
Прежде всего, SQL не является процедурным языком (хотя в промышленных СУБД и реализована возможность создания процедур на SQL). Каждый запрос определяет, что нужно сделать с данными и выполняется сам по себе, а не является последовательностью инструкций. Например, простейший запрос, который выведет все содержимое таблицы BILL, будет выглядеть следующим образом:
SELECT * FROM BILL
При этом все операции по интерпретации и выполнению запроса выполняются СУБД, а приложению остается лишь отсылать запросы и отображать их результаты. В данном случае был использован один из основных операторов SQL - SELECT. Всего в SQL имеется 3 группы операторов:
- Операторы управления данными (Data Manipulation Language, DML), служащие для выполнения поиска, удаления, изменения и сохранения данных. Помимо SELECT, к ним относятся UPDATE, INSERT и DELETE.
- Операторы определения данных (Data Definition Language, DDL), которые используются для создания объектов БД и изменения их структуры. Это операторы CREATE TABLE, CREATE VIEW, CREATE DOMAIN и т.д.
- Операторы контроля данных (Data Control Statements, DCS), использующиеся для контроля прав доступа к данным - GRANT и REVOKE.
Кроме них, в SQL имеются дополнительные операторы, служащие для управления транзакциями, сеансами, соединениями и т.д. Набор операторов SQL, как и их синтаксис может варьироваться в зависимости от применяемой СУБД. И хотя практически все СУБД поддерживают основной набор и синтаксис операторов, определенных в действующем стандарте ANSI SQL, они могут иметь собственные расширения языка и особенности реализации тех или иных стандартных процедур.
ПРИМЕЧАНИЕ
К сожалению, в рамках настоящего издания мы не сможем детально изучить язык SQL, поскольку он сам по себе представляет очень емкую тему. И если вы планируете создавать клиент-серверные БД, то он вам будет необходимо обратиться к дополнительным источникам информации, поскольку работа с такими БД строится именно на основе SQL.
Еще одним отличием SQL от других языков программирования является его тройственная логика. В частности, помимо значений False и True (ложь и истина), логические переменные могут содержать значение Unknown (неизвестно), что соответствует пустой ячейке таблицы или специальному значению Null.
И хотя те СУБД, с которыми мы, преимущественно, будем сталкиваться по ходу дальнейшего изучения баз данных, не являются основанными на SQL, среда Delphi позволяет работать с ними не только собственными средствами, но так же и при помощи языка SQL, пусть и с некоторыми ограничениями. В то же время основная масса примеров будет обходиться без SQL-запросов вообще, опираясь лишь на средства локальных СУБД и на инструментарий, имеющийся в Delphi.